引言
锁!这个词汇在编程中出现的次数尤为频繁,几乎主流的编程语言都会具备完善的锁机制,在数据库中也并不例外,为什么呢?这里牵扯到一个关键词:高并发,由于现在的计算机领域几乎都是多核机器,因此再编写单线程的应用自然无法将机器性能发挥到最大,想要让程序的并发性越高,多线程技术自然就呼之欲出,多线程技术一方面能充分压榨CPU资源,另一方面也能提升程序的并发支持性。

多线程技术虽然能带来一系列的优势,但也因此引发了一个致命问题:线程安全问题,为了解决多线程并发执行造成的这个问题,从而又引出了锁机制,通过加锁执行的方式解决这类问题。
多线程、线程安全问题、锁机制,这都是咱们的老朋友了,相信之前曾认真读过《并发编程系列》相关文章的小伙伴都并不陌生,而本章则主要讲解MySQL中提供的锁机制。
MySQL锁的由来与分类
客户端发往MySQL的一条条SQL语句,实际上都可以理解成一个个单独的事务,而在前面的《MySQL事务篇》中提到过:事务是基于数据库连接的,而每个数据库连接在MySQL中,又会用一条工作线程来维护,也意味着一个事务的执行,本质上就是一条工作线程在执行,当出现多个事务同时执行时,这种情况则被称之为并发事务,所谓的并发事务也就是指多条线程并发执行。
多线程并发执行自然就会出问题,也就是《事务篇-并发事务问题》中聊到的脏写、脏读、不可重复读以及幻读问题,而对于这些问题又可以通过调整事务的隔离级别来避免,那为什么调整事务的隔离级别后能避免这些问题产生呢?这是因为不同的隔离级别中,工作线程执行SQL语句时,用的锁粒度、类型不同。
也就是说,数据库的锁机制本身是为了解决并发事务带来的问题而诞生的,主要是确保数据库中,多条工作线程并行执行时的数据安全性。
但要先弄明白一点,所谓的并发事务肯定是基于同一个数据而言的,例如事务A目前在操作X表,事务B在操作Y表,这是一个并发事务吗?答案显然并不是,因为两者操作的都不是同一个数据,没有共享资源自然也不会造成并发问题。多个事务共同操作一张表、多个事务一起操作同一行数据等这类情景,这才是所谓的并发事务。
MySQL锁机制的分类
MySQL的锁机制与索引机制类似,都是由存储引擎负责实现的,这也就意味着不同的存储引擎,支持的锁也并不同,这里是指不同的引擎实现的锁粒度不同。但除开从锁粒度来划分锁之外,其实锁也可以从其他的维度来划分,因此也会造出很多关于锁的名词,下面先简单梳理一下MySQL的锁体系:
- 以锁粒度的维度划分:
- 表锁:
- 全局锁:加上全局锁之后,整个数据库只能允许读,不允许做任何写操作。
- 元数据锁 / MDL锁:基于表的元数据加锁,加锁后整张表不允许其他事务操作。
- 意向锁:这个是InnoDB中为了支持多粒度的锁,为了兼容行锁、表锁而设计的。
- 自增锁 / AUTO-INC锁:这个是为了提升自增ID的并发插入性能而设计的。
- 页面锁
- 行锁:
- 记录锁 / Record锁:也就是行锁,一条记录和一行数据是同一个意思。
- 间隙锁 / Gap锁:InnoDB中解决幻读问题的一种锁机制。
- 临建锁 / Next-Key锁:间隙锁的升级版,同时具备记录锁+间隙锁的功能。
- 表锁:
- 以互斥性的维度划分:
- 共享锁 / S锁:不同事务之间不会相互排斥、可以同时获取的锁。
- 排他锁 / X锁:不同事务之间会相互排斥、同时只能允许一个事务获取的锁。
- 共享排他锁 / SX锁:MySQL5.7版本中新引入的锁,主要是解决SMO带来的问题。
- 以操作类型的维度划分:
- 读锁:查询数据时使用的锁。
- 写锁:执行插入、删除、修改、DDL语句时使用的锁。
- 以加锁方式的维度划分:
- 显示锁:编写SQL语句时,手动指定加锁的粒度。
- 隐式锁:执行SQL语句时,根据隔离级别自动为SQL操作加锁。
- 以思想的维度划分:
- 乐观锁:每次执行前认为自己会成功,因此先尝试执行,失败时再获取锁。
- 悲观锁:每次执行前都认为自己无法成功,因此会先获取锁,然后再执行。
放眼望下来,是不是看着还蛮多的,但总归说来说去其实就共享锁、排他锁两种,只是加的方式不同,加的地方不同,因此就演化出了这么多锁的称呼。
共享锁与排他锁
共享锁又被称之为S锁,它是Shared Lock的简称,这点很容易理解,而排他锁又被称之为X锁,对于这点我则不太理解,因为排他锁的英文是Exclusive Lock,竟然不叫E锁,反而叫X锁,到底是红杏出了墙还是…,打住,回归话题本身来聊一聊这两种锁。
其实有些地方也将共享锁称之为读锁,排他锁称之为写锁,这乍一听并没啥问题,毕竟对同一数据做读操作是可以共享的,写则是不允许。但这个说法并不完全正确,因为读操作也可以是排他锁,即读操作发生时也不允许其他线程操作,而MySQL中也的的确确有这类场景,比如:
一条线程在读数据时加了一把锁(读锁),此时当另外一条线程来尝试对相同数据做写操作时,这条线程会陷入阻塞,因为MySQL中一条线程在读时不允许其他线程改。
在上述这个案例中,读锁明显也会存在排斥写操作,因此前面说法并不正确,共享锁就是共享锁,排他锁就是排他锁,不能与读锁、写锁混为一谈。
共享锁
共享锁的意思很简单,也就是不同事务之间不会排斥,可以同时获取锁并执行,这就类似于之前聊过的《AQS-共享模式》,但这里所谓的不会排斥,仅仅只是指不会排斥其他事务来读数据,但其他事务尝试写数据时,就会出现排斥性,举个例子理解:
事务T1对ID=88的数据加了一个共享锁,此时事务T2、T3也来读取ID=88的这条数据,这时T2、T3是可以获取共享锁执行的,但此刻又来了一个事务T4,它则是想对ID=88的这条数据执行修改操作,此时共享锁会出现排斥行为,不允许T4获取锁执行。
在MySQL中,我们可以在SQL语句后加上相关的关键字来使用共享锁,语法如下:
SELECT ... LOCK IN SHARE MODE;
-- MySQL8.0之后也优化了写法,如下:
SELECT ... FOR SHARE;
这种通过在SQL后添加关键字的加锁形式,被称为显式锁,而实际上为数据库设置了不同的事务隔离级别后,MySQL也会对SQL自动加锁,这种形式则被称之为隐式锁。
此时来做个关于共享锁的小实验,先打开两个cmd窗口并与MySQL建立连接:
-- 窗口1:
-- 开启一个事务
begin;
-- 获取共享锁并查询 ID=1 的数据
select * from `zz_users` where user_id = 1 lock in share mode;
-- 窗口2:
-- 开启一个事务
begin;
-- 获取共享锁并查询 ID=1 的数据
select * from `zz_users` where user_id = 1 lock in share mode;
此时两个事务都是执行查询的操作,因此可以正常执行,如下:

紧接着再在窗口2中,尝试修改ID=1的数据:
-- 修改 ID=1 的姓名为 猫熊
update `zz_users` set `user_name` = "猫熊" where `user_id` = 1;
此时执行后会发现,窗口2没了反应,这条写SQL显然并未执行成功,如下:
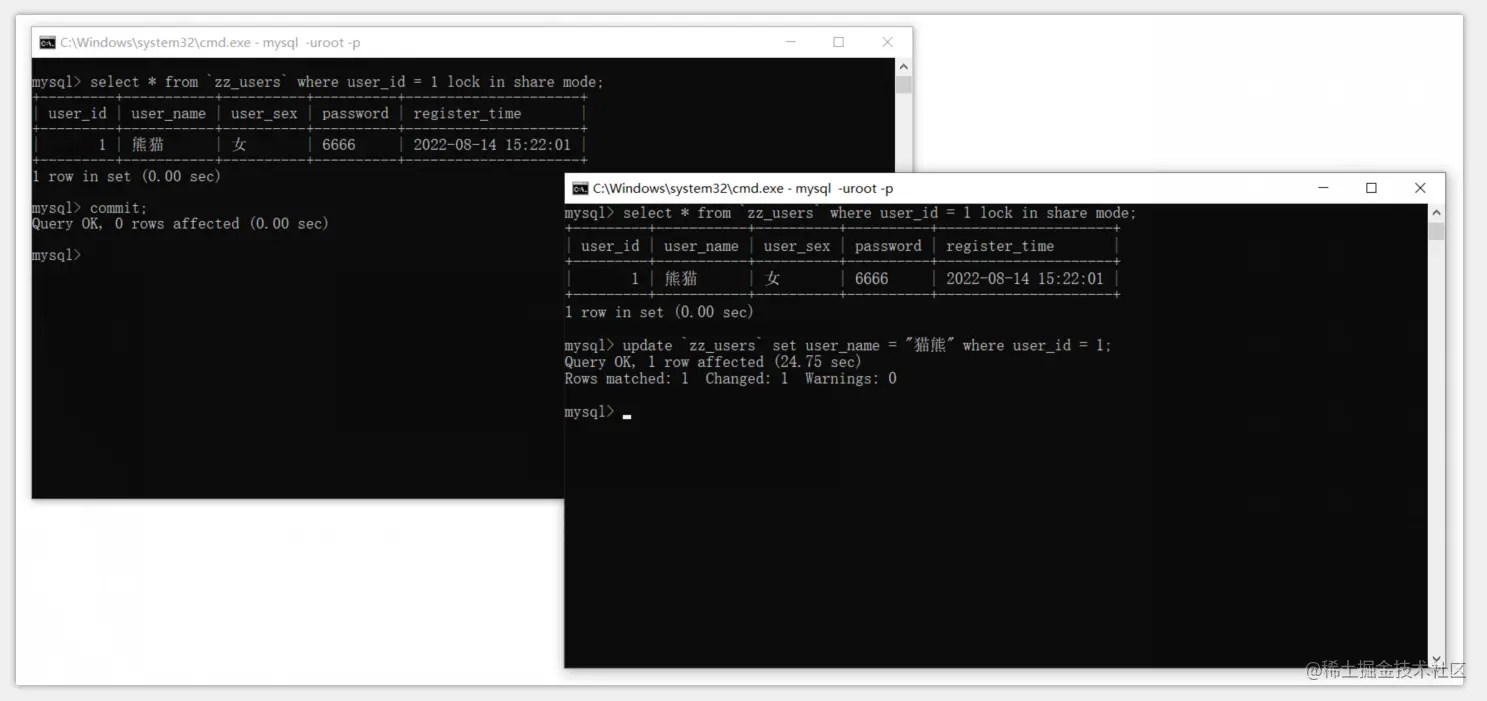
显然当另一个事务尝试对具备共享锁的数据进行写操作时,会被共享锁排斥,因此从这个实验中可以得知:共享锁也具备排他性,会排斥其他尝试写的线程,当有线程尝试修改同一数据时会陷入阻塞,直至持有共享锁的事务结束才能继续执行,如下:

当第一个持有共享锁的事务提交后,此时第二个事务的写操作才能继续往下执行,从上述截图中可明显得知:第二个事务/线程被阻塞24.74s后才执行成功,这是由于第一个事务迟迟未结束导致的。
排他锁
上面简单的了解了共享锁之后,紧着来看看排他锁,排他锁也被称之为独占锁,也就是类似于之前所讲到的《AQS-独占模式》,当一个线程获取到独占锁后,会排斥其他线程,如若其他线程也想对共享资源/同一数据进行操作,必须等到当前线程释放锁并竞争到锁资源才行。
值得注意的一点是:排他锁并不是只能用于写操作,对于一个读操作,咱们也可以手动的指定为获取排他锁,当一个事务在读数据时,获取了排他锁,那当其他事务来读、写同一数据时,都会被排斥,比如事务T1对ID=88的这条数据加了一个排他锁,此时T2来加排他锁读取这条数据,T3来修改这条数据,都会被T1排斥。
在MySQL中,可以通过如下方式显式获取独占锁:
SELECT ... FOR UPTATE;
也简单的做个小实验,如下:

当两个事务同时获取排他锁,尝试读取一条相同的数据时,其中一个事务就会陷入阻塞,直至另一个事务结束才能继续往下执行,但是下述这种情况则不会被阻塞:

也就是另一个事务不获取排他锁读数据,而是以普通的方式读数据,这种方式则可以立刻执行,Why?是因为读操作默认加共享锁吗?也并不是,因为你尝试加共享锁读这条数据时依旧会被排斥,如下:
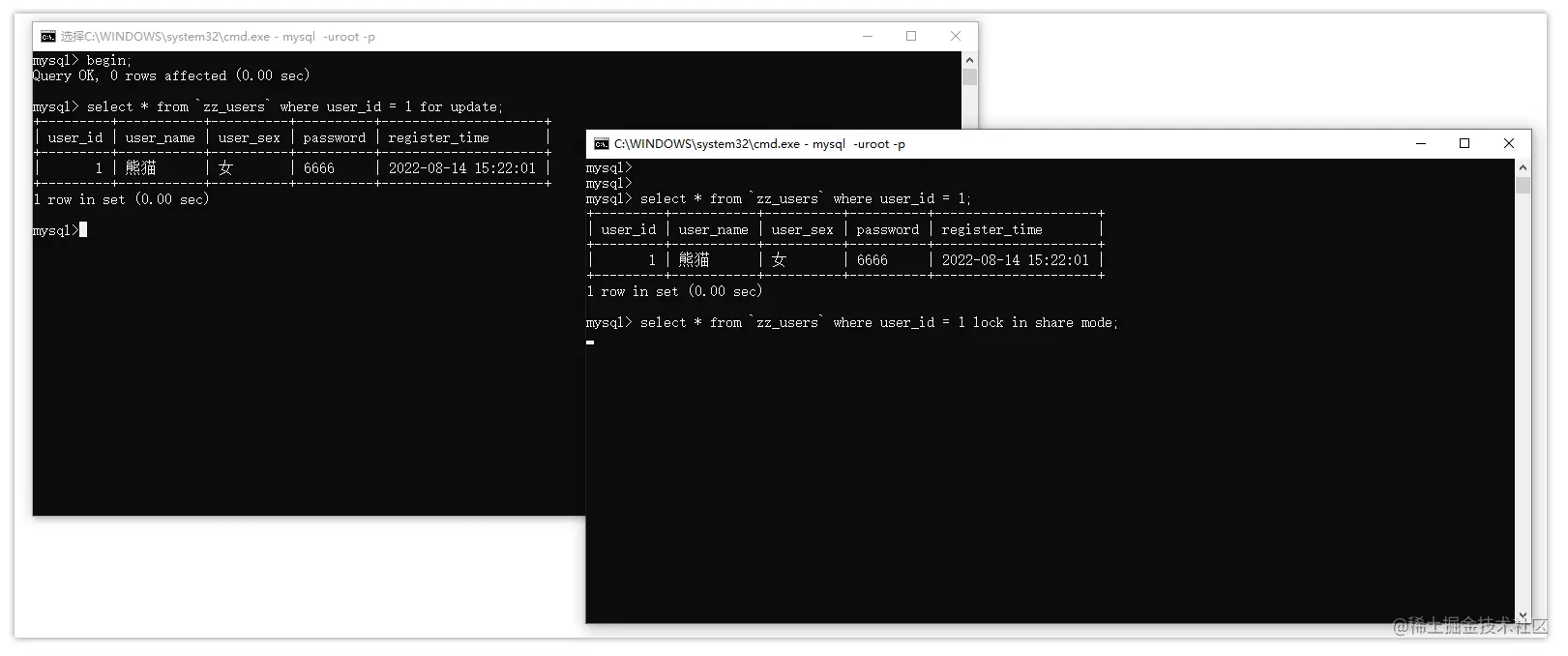
可以明显看到,第二个事务中尝试通过加共享锁的方式读取这条数据,依旧会陷入阻塞状态,那前面究竟是因为啥原因才导致的能读到数据呢?其实这跟另一种并发控制技术有关,即MVCC机制(下篇再深入剖析)。
MySQL锁的释放
等等,似乎在咱们前面的实验中,每次都仅获取了锁,但好像从未释放过锁呀?其实MySQL中释放锁的动作都是隐式的,毕竟如果交给咱们来释放,很容易由于操作不当造成死锁问题发生。因此对于锁的释放工作,MySQL自己来干,就类似于JVM中的GC机制一样,把内存释放的工作留给了自己完成。
但对于锁的释放时机,在不同的隔离级别中也并不相同,比如在“读未提交”级别中,是SQL执行完成后就立马释放锁,而在“可重复读”级别中,是在事务结束后才会释放。
OK~,接下来一起来聊一聊MySQL中不同粒度的锁,即表锁、行锁、页锁等。
MySQL表锁
表锁应该是听的最多的一种锁,因为实现起来比较简单,同时应用范围也比较广泛,几乎所有的存储引擎都会支持这个粒度的锁,比如常用的MyISAM、InnoDB、Memory等各大引擎都实现了表锁。
但要注意,不同引擎的表锁也在实现上以及加锁方式上有些许不同,但归根结底,表锁的意思也就以表作为锁的基础,将锁加在表上,一张表只能存在一个同一类型的表锁。
上面这段话中提到过,不同的存储引擎的表锁在使用方式上也有些不同,比如InnoDB是一个支持多粒度锁的存储引擎,它的锁机制是基于聚簇索引实现的,当SQL执行时,如果能在聚簇索引命中数据,则加的是行锁,如无法命中聚簇索引的数据则加的是表锁,比如:
select * from `zz_users` for update;
这条SQL就无法命中聚簇索引,此时自然加的就是表级别的排他锁,但是这个表级锁,并不是真正意义上的表锁,是一个“伪表锁”,但作用是相同的,锁了整张表。
而反观MyISAM引擎,由于它并不支持聚簇索引,所以无法再以InnoDB的这种形式去对表上锁,因此如若要在MyISAM引擎中使用表锁,又需要使用额外的语法,如下:
-- MyISAM引擎中获取读锁(具备读-读可共享特性)
LOCK TABLES `table_name` READ;
-- MyISAM引擎中获取写锁(具备写-读、写-写排他特性)
LOCK TABLES `table_name` WRITE;
-- 查看目前库中创建过的表锁(in_use>0表示目前正在使用的表锁)
SHOW OPEN TABLES WHERE in_use > 0;
-- 释放已获取到的锁
UNLOCK TABLES;
如上便是MyISAM引擎中,获取表级别的共享锁和排他锁的方式,但这里的关键词其实叫做READ、WEITE,翻译过来也就是读、写的意思,因此关于共享锁就是读锁、排他锁就是写锁的说法,估计就是因此而来的。
不过MyISAM引擎中,获取了锁还需要自己手动释放锁,否则会造成死锁现象出现,因为如果不手动释放锁,就算事务结束也不会自动释放,除非当前的数据库连接中断时才会释放。
此时来观察一个小实验,代码和步骤就不贴了,重点看图,如下:

如若你自己有兴趣,也可以按照上图中的序号一步步实验,从这个实验结果中,显然能佐证咱们前面抛出的观点,MyISAM表锁显式获取后,必须要自己主动释放,否则结合数据库连接池,由于数据库连接是长存的,就会导致表锁一直被占用。
这里还漏了一个小实验,也就是当你加了read读锁后,再尝试加write写锁,就会发现无法获取锁,当前线程会陷入阻塞,反过来也是同理,但我就不再重新再弄了,毕竟这个图再搞一次就有点累~
OK~,到这里就对InnoDB、MyISAM引擎中的表锁做了简单介绍,但实际上除开最基本的表锁外,还有其他几种表锁,即元数据锁、意向锁、自增锁、全局锁,接下来一起来聊一聊这些特殊的锁。
元数据锁(Meta Data Lock)
Meta Data Lock元数据锁,也被简称为MDL锁,这是基于表的元数据加锁,什么意思呢?咱们到目前为止已经模模糊糊懂得一个概念:表锁是基于整张表加锁,行锁是基于一条数据加锁,那这个表的元数据是什么东东呢?在《索引原理篇》中聊索引的实现时,曾提到过一点:所有存储引擎的表都会存在一个.frm文件,这个文件中主要存储表的结构(DDL语句),而DML锁就是基于.frm文件中的元数据加锁的。
对于这种锁是在MySQL5.5版本后再开始支持的,一般来说咱们用不上,因此也无需手动获取锁,这个锁主要是用于:更改表结构时使用,比如你要向一张表创建/删除一个索引、修改一个字段的名称/数据类型、增加/删除一个表字段等这类情况。
因为毕竟当你的表结构正在发生更改,假设此时有其他事务来对表做CRUD操作,自然就会出现问题,比如我刚删了一个表字段,结果另一个事务中又按原本的表结构插入了一条数据,这显然会存在风险,因此DML锁在加锁后,整张表不允许其他事务做任何操作。
意向锁(Intention Lock)
前面提到过,InnoDB引擎是一种支持多粒度锁的引擎,而意向锁则是InnoDB中为了支持多粒度的锁,为了兼容行锁、表锁而设计的,怎么理解这句话呢?先来看一个例子:
假设一张表中有一千万条数据,现在事务T1对ID=8888888的这条数据加了一个行锁,此时来了一个事务T2,想要获取这张表的表级别写锁,经过前面的一系列讲解,大家应该知道写锁必须为排他锁,也就是在同一时刻内,只允许当前事务操作,如果表中存在其他事务已经获取了锁,目前事务就无法满足“独占性”,因此不能获取锁。
那思考一下,由于T1是对ID=8888888的数据加了行锁,那T2获取表锁时,是不是得先判断一下表中是否存在其他事务在操作?但因为InnoDB中有行锁的概念,所以表中任何一行数据上都有可能存在事务加锁操作,为了能精准的知道答案,MySQL就得将整张表的1000W条数据全部遍历一次,然后逐条查看是否有锁存在,那这个效率自然会非常的低。
有人可能会说,慢就慢点怎么了,能接受!但实际上不仅仅存在这个问题,还有另外一个致命问题,比如现在MySQL已经判断到了第567W行数据,发现前面的数据上都没有锁存在,正在继续往下遍历。
要记住MySQL是支持并发事务的,也就是MySQL正在扫描后面的每行数据是否存在锁时,万一又来了一个事务在扫描过的数据行上加了个锁怎么办?比如在第123W条数据上加了一个行锁。那难道又重新扫描一遍嘛?这就陷入了死循环,行锁和表锁之间出现了兼容问题。
也正是由于行锁和表锁之间存在兼容性问题,所以意向锁它来了!意向锁实际上也是一种特殊的表锁,意向锁其实是一种“挂牌告知”的思想,好比日常生活中的出租车,一般都会有一个牌子,表示它目前是“空车”还是“载客”状态,而意向锁也是这个思想。
比如当事务T1打算对ID=8888888这条数据加一个行锁之前,就会先加一个表级别的意向锁,比如目前T1要加一个行级别的读锁,就会先添加一个表级别的意向共享锁,如果T1要加行级别的写锁,亦是同理。
此时当事务T2尝试获取一个表级锁时,就会先看一下表上是否有意向锁,如果有的话再判断一下与自身是否冲突,比如表上存在一个意向共享锁,目前T2要获取的是表级别的读锁,那自然不冲突可以获取。但反之,如果T2要获取一个表记的写锁时,就会出现冲突,T2事务则会陷入阻塞,直至T1释放了锁(事务结束)为止。
自增锁(AUTO-INC Lock)
自增锁,这个是专门为了提升自增ID的并发插入性能而设计的,通常情况下咱们在建表时,都会对一张表的主键设置自增特性,如下:
CREATE TABLE `table_name` (
`xx_id` NOT NULL AUTO_INCREMENT,
.....
) ENGINE = InnoDB;
当对一个字段设置AUTO_INCREMENT自增后,意味着后续插入数据时无需为其赋值,系统会自动赋上顺序自增的值。但想一想,比如目前表中最大的ID=88,如果两个并发事务一起对表执行插入语句,由于是并发执行的原因,所以有可能会导致插入两条ID=89的数据。因此这里必须要加上一个排他锁,确保并发插入时的安全性,但也由于锁的原因,插入的效率也就因此降低了,毕竟将所有写操作串行化了。
为了改善插入数据时的性能,自增锁诞生了,自增锁也是一种特殊的表锁,但它仅为具备AUTO_INCREMENT自增字段的表服务,同时自增锁也分成了不同的级别,可以通过innodb_autoinc_lock_mode参数控制。
- innodb_autoinc_lock_mode = 0:传统模式。
- innodb_autoinc_lock_mode = 1:连续模式(MySQL8.0以前的默认模式)。
- innodb_autoinc_lock_mode = 2:交错模式(MySQL8.0之后的默认模式)。
当然,这三种模式又是什么含义呢?想要彻底搞清楚,那就得先弄明白MySQL中可能出现的三种插入类型:
- 普通插入:指通过INSERT INTO table_name(…) VALUES(…)这种方式插入。
- 批量插入:指通过INSERT … SELECT …这种方式批量插入查询出的数据。
- 混合插入:指通过INSERT INTO table_name(id,…) VALUES(1,…),(NULL,…),(3,…)这种方式插入,其中一部分指定ID,一部分不指定。
简单了解上述三种插入模式后,再用一句话来概述自增锁的作用:自增锁主要负责维护并发事务下自增列的顺序,也就是说,每当一个事务想向表中插入数据时,都要先获取自增锁先分配一个自增的顺序值,但不同模式下的自增锁也会有些许不同。
传统模式:事务T1获取自增锁插入数据,事务T2也要插入数据,此时事务T2只能阻塞等待,也就是传统模式下的自增锁,同时只允许一条线程执行,这种形式显然性能较低。
连续模式:这个模式主要是由于传统模式存在性能短板而研发的,在这种模式中,对于能够提前确定数量的插入语句,则不会再获取自增锁,啥意思呢?也就是对于“普通插入类型”的语句,因为在插入之前就已经确定了要插入多少条数据,因为会直接分配范围自增值。
好比目前事务T1要通过INSERT INTO…语句插入十条数据,目前表中存在的最大ID=88,那在连续模式下,MySQL会直接将89~98这十个自增值分配给T1,因此T1无需再获取自增锁,但不获取自增锁不代表不获取锁了,而是改为使用一种轻量级锁Mutex-Lock来防止自增值重复分配。
对于普通插入类型的操作,由于可以提前确定插入的数据量,因此可以采用“预分配”思想,但如若对于批量插入类型的操作,因为批量插入的数据是基于SELECT语句查询出来的,所以在执行之前也无法确定究竟要插入多少条,所以依旧会获取自增锁执行。也包括对于混合插入类型的操作,有一部分指定了自增值,但有一部分需要MySQL分配,因此“预分配”的思想也用不上,因此也要获取自增锁执行。
交错模式:在交错插入模式中,对于INSERT、REPLACE、INSERT…SELECT、REPLACE…SELECT、LOAD DATA等一系列插入语句,都不会再使用表级别的自增锁,而是全都使用Mutex-Lock来确保安全性,为什么在这个模式中,批量插入也可以不获取自增锁呢?这跟它的名字有关,目前这个模式叫做交错插入模式,也就是不同事务之间插入数据时,自增列的值是交错插入的,举个例子理解。
好比事务T1、T2都要执行批量插入的操作,因为不确定各自要插入多少条数据,所以之前那种“连续预分配”的思想用不了了,但虽然无法做“连续的预分配”,那能不能交错预分配呢?好比给T1分配{1、3、5、7、9…},给T2分配{2、4、6、8、10…},然后两个事务交错插入,这样岂不是做到了自增值即不重复,也能支持并发批量插入?答案是Yes,但由于两个事务执行的都是批量插入的操作,因此事先不确定插入行数,所以有可能导致“交错预分配”的顺序值,有可能不会使用,比如T1只插入了四条数据,只用了1、3、5、7,T2插入了五条数据,因此表中的自增值有可能出现空隙,即{1、2、3、4、5、6、8、10},其中9就并未使用。
虽然我没看过自增锁这块的源码,但交错插入模式底层应该是我推测的这种方式实现的,也就是利用自增列的步长机制实现,不过由于插入可能会出现空隙,因此对后续的主从复制也有一定影响(以后再细聊)。
不过相对来说影响也不大,虽然无法保证自增值的连续性,但至少能确保递增性,因此对索引的维护不会造成额外开销。
全局锁
全局锁其实是一种尤为特殊的表锁,其实将它称之为库锁也许更合适,因为全局锁是基于整个数据库来加锁的,加上全局锁之后,整个数据库只能允许读,不允许做任何写操作,一般全局锁是在对整库做数据备份时使用。
-- 获取全局锁的命令
FLUSH TABLES WITH READ LOCK;
-- 释放全局锁的命令
UNLOCK TABLES;
从上述的命令也可以看出,为何将其归纳到表锁范围,因为获取锁以及释放锁的命令都是表锁的命令。
MySQL行锁
通常而言,为了尽可能提升数据库的整体性能,所以每次在加锁时,锁的范围自然是越小越好,举个例子:
假设此时有1000个请求,要操作zz_users表中的数据,如果以表粒度来加锁,假设第一个请求获取到的是排他锁,也就意味着其他999个请求都需要阻塞等待,其效率可想而知…
仔细一思考:虽然此时有1000个请求操作zz_users表,但这些请求中至少90%以上,要操作的都是表中不同的行数据,因此如若每个请求都获取表级锁,显然太影响效率了,而InnoDB引擎中也考虑到了这个问题,所以实现了更细粒度的锁,即行锁。
表锁与行锁之间的关系
表锁与行锁之间的关系,举个生活中的例子来快速理解一下,一张表就类似于一个生活中的酒店,每个事务/请求就类似于一个个旅客,旅客住宿为了确保夜晚安全,通常都会锁门保护自己。而表锁呢,就类似于一个旅客住进酒店之后,直接把酒店大门给锁了,其他旅客就只能等第一位旅客住完出来之后才能一个个进去,每个旅客进酒店之后的第一件事情就是锁大门,防止其他旅客威胁自己的安全问题。
但假设酒店门口来了一百位旅客,其中大部分旅客都是不同的房间(情侣除外),因此直接锁酒店大门显然并不合理。
而行锁呢,就类似于房间的锁,门口的100位旅客可以一起进酒店,每位旅客住进自己的房间之后,将房门反锁,这显然也能保障各自的人身安全问题,同时也能让一个酒店在同一时间内接纳更多的旅客,“性能”更高。
InnoDB的行锁实现
放眼望去,在MySQL诸多的存储引擎中,仅有InnoDB引擎支持行锁(不考虑那些闭源自研的),这是由于什么原因导致的呢?因为InnoDB支持聚簇索引,在之前简单聊到过,InnoDB中如果能够命中索引数据,就会加行锁,无法命中则会加表锁。
在《索引原理篇-InnoDB索引实现》中提到过,InnoDB会将表数据存储在聚簇索引中,每条行数据都会存储在树中的叶子节点上,因此行数据是“分开的”,所以可以对每一条数据上锁,但其他引擎大部分都不支持聚簇索引,表数据都是一起存储在一块的,所以只能基于整个表数据上锁,这也是为什么其他引擎不支持行锁的原因。
记录锁(Record Lock)
Record Lock记录锁,实际上就是行锁,一行表数据、一条表记录本身就是同一个含义,因此行锁也被称为记录锁,两个称呼最终指向的是同一类型的锁,那如何使用行锁呢?
-- 获取行级别的 共享锁
select * from `zz_users` where user_id = 1 lock in share mode;
-- 获取行级别的 排他锁
select * from `zz_users` where user_id = 1 for update;
是的,你没看错,想要使用InnoDB的行锁就是这样写的,如果你的SQL能命中索引数据,那也就自然加的就是行锁,反之则是表锁。但网上很多资料都流传着一个说法:InnoDB引擎的表锁没啥用,其实这句话会存在些许误导性,因为意向锁、自增锁、DML锁都是表锁,也包括InnoDB的行锁是基于索引实现的,例如在update语句修改数据时,假设where后面的条件无法命中索引,那咋加行锁呢?此时没办法就必须得加表锁了,因此InnoDB的表锁是有用的。
间隙锁(Gap Lock)
间隙锁是对行锁的一种补充,主要是用来解决幻读问题的,但想要理解它,咱们首先来理解啥叫间隙:
SELECT * FROM `zz_users`;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
| 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
| 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
| 4 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:59 |
| 9 | 黑竹 | 男 | 9999 | 2022-09-28 22:31:44 |
+---------+-----------+----------+----------+---------------------+
上述这张表最后两条数据,ID字段之间从4跳到了9,那么4~9两者之间的范围则被称为“间隙”,而间隙锁则主要锁定的是这块范围。
那为何又说间隙锁是用来解决幻读问题的呢?因为幻读的概念是:一个事务在执行时,另一个事务插入了一条数据,从而导致第一个事务操作完成之后发现结果与预想的不一致,跟产生了幻觉一样。
好比拿上述表举例子,现在要将ID>3的用户密码重置为1234,因此事务T1先查到了ID>3的4、9两条数据并上锁了,然后开始更改用户密码,但此时事务T2过来又插入了一条ID=6、password=7777的数据并提交,等T1修改完了4、9两条数据后,此时再次查询ID>3的数据时,结果发现了ID=6的这条数据并未被重置密码。
在上述这个例子中,T2因为新增并提交了事务,所以T1再次查询时也能看到ID=6的这条数据,就跟产生了幻觉似的,对于这种新增数据,专业的叫法称之为幻影数据。
为了防止出现安全问题,所以T1在操作之前会对目标数据加锁,但在T1事务执行时,这条幻影数据还不存在,因此就会出现一个新的问题:不知道把锁加在哪儿,毕竟想要对ID=6的数据加锁,就是加了个寂寞。
那难道不加锁了吗?肯定得加锁,但怎么加呢?普通的行锁就已经无法解决这个问题了,总不能加表锁吧,那也太影响性能了,所以间隙锁应运而生!间隙锁的功能与它的名字一样,主要是对间隙区域加锁,举个例子:
select * from `zz_users` where user_id = 6 lock in share mode;
这条加锁的SQL看起来似乎不是那么合理对吧?毕竟ID=6的数据在表中还没有呀,咋加锁呢?其实这个就是间隙锁,此时会锁定{4~9}之间、但不包含4、9的区域,因为间隙锁是遵循_左右开区间_的原则,简单演示一下案例:
上述案例的过程参考图中注释即可,不再反复赘述,简单说一下结论:当对一个不存在的数据加锁后,默认就是锁定前后两条数据之间的区间,当其他事务再尝试向该区间插入数据时,就会陷入阻塞,只有当持有间隙锁的事务结束后,才能继续执行插入操作。
不过间隙锁加在不同的位置,锁定的范围也并不相同,如果加在两条数据之间,那么锁定的区域就是两条数据之间的间隙。如果加在上表ID=1的数据上,锁定的区域就是{-∞ ~ 1},即无穷小到1之间的区域。如果加在ID=9之后,锁定的区域就是{9 ~ +∞},即9之后到无穷大的区域。
临键锁(Next-Key Lock)
临键锁是间隙锁的Plus版本,或者可以说成是一种由记录锁+间隙锁组成的锁:
- 记录锁:锁定的范围是表中具体的一条行数据。
- 间隙锁:锁定的范围是左开右闭的区间,并不包含最后一条真实数据。
而临键锁则是两者的结合体,加锁后,即锁定左开右闭的区间,也会锁定当前行数据,还是以上述表为例,做个简单的小实验,如下:

这回和间隙锁的实验类似,但也并不相同,这回是基于表中ID=9的这条数据加锁的,此时来看结果,除开锁定了4~9这个区间外,对于ID=9这条数据也锁定了,因为在事务T2中尝试对ID=9的数据修改时,也会让事务陷入阻塞。
临键锁的注意点:当原本持有锁的T1事务结束后,T2会执行插入操作,这时锁会被T2获取,当你再尝试开启一个新的事务T3,再次获取相同的临键锁时,是无法获取的,只能等T2结束后才能获取(因为临建锁包含了记录锁,虽然间隙锁可以同时由多个事务持有,但排他类型的记录锁只允许一个事务持有)。
实际上在InnoDB中,除开一些特殊情况外,当尝试对一条数据加锁时,默认加的是临键锁,而并非记录锁、间隙锁。
也就是说,在前面举例幻读问题中,当T1要对ID>3的用户做密码重置,锁定4、9这两条行数据时,默认会加的是临键锁,也就是当事务T2尝试插入ID=6的数据时,因为有临建锁存在,因此无法再插入这条“幻影数据”,也就至少保障了T1事务执行过程中,不会碰到幻读问题。
插入意向锁(Insert Intention Lock)
插入意向锁,听起来似乎跟前面的表级别意向锁有些类似,但实际上插入意向锁是一种间隙锁,这种锁是一种隐式锁,也就是咱们无法手动的获取这种锁。通常在MySQL中插入数据时,是并不会产生锁的,但在插入前会先简单的判断一下,当前事务要插入的位置有没有存在间隙锁或临键锁,如果存在的话,当前插入数据的事务则需阻塞等待,直到拥有临键锁的事务提交。
当事务执行插入语句阻塞时,就会生成一个插入意向锁,表示当前事务想对一个区间插入数据(目前的事务处于等待插入意向锁的状态)。
当持有原本持有临建锁的事务提交后,当前事务即可以获取插入意向锁,然后执行插入操作,当此时如若又来一个新的事务,也要在该区间中插入数据,那新的事务会阻塞吗?答案是不会,可以直接执行插入操作,Why?
因为在之前的《SQL执行篇-写入SQL执行流程》中曾说到过,对于写入SQL都会做一次唯一性检测,如果要插入的数据,与表中已有的数据,存在唯一性冲突时会直接抛出异常并返回。这也就意味着:如果没抛出异常,就代表着当前要插入的数据与表中数据不存在唯一性冲突,或表中压根不存在唯一性字段,可以允许插入重复的数据。
简单来说就是:能够真正执行的插入语句,绝对是通过了唯一检测的,因此插入时可以让多事务并发执行,同时如果设置了自增ID,也会获取自增锁确保安全性,所以当多个事务要向一个区间插入数据时,插入意向锁是不会排斥其他事务的,从这种角度而言,插入意向锁也是一种共享锁。
行锁的粒度粗化
有一点要值得注意:行锁并不是一成不变的,行锁会在某些特殊情况下发生粗化,主要有两种情况:
- 在内存中专门分配了一块空间存储锁对象,当该区域满了后,就会将行锁粗化为表锁。
- 当做范围性写操作时,由于要加的行锁较多,此时行锁开销会较大,也会粗化成表锁。
当然,这两种情况其实很少见,因此只需要知道有锁粗化这回事即可,这种锁粗化的现象其实在SQLServer数据库中更常见,因为SQLServer中的锁机制是基于行记录实现的,而MySQL中的锁机制则是基于事务实现的(后续《事务与锁原理篇》详细剖析)。
页面锁、乐观锁与悲观锁
上述对MySQL两种较为常见的锁粒度进行了阐述,接着再来看看页面锁、乐观锁与悲观锁。
页面锁
页面锁是Berkeley DB存储引擎支持的一种锁粒度,当然,由于BDB引擎被Oracle收购的原因,因此MySQL5.1以后不再直接性的支持该引擎(需自己整合),因此页锁见的也比较少,大家稍微了解即可。
- 表锁:以表为粒度,锁住的是整个表数据。
- 行锁:以行为粒度,锁住的是一条数据。
- 页锁:以页为粒度,锁住的是一页数据。
唯一有些许疑惑的地方,就是一页数据到底是多少呢?其实我也不大清楚,毕竟没用过BDB引擎,但我估计就是只一个索引页的大小,即16KB左右。
简单了解后页锁后,接着来看一看从思想维度划分的两种锁,即乐观锁与悲观锁。
乐观锁
乐观锁即是无锁思想,对于这点在之前聊《并发编程系列-Unsafe与原子包》时曾详细讲到过,但悲观锁也好,乐观锁也罢,实际上仅是一种锁的思想,如下:
- 乐观锁:每次执行都认为只会有自身一条线程操作,因此无需拿锁直接执行。
- 悲观锁:每次执行都认为会有其他线程一起来操作,因此每次都需要先拿锁再执行。
乐观锁与悲观锁也对应着咱们日常生活中,处理一件事情的态度,一个人性格很乐观时,做一件事情时都会把结果往好处想,而一个人性格很悲观时,处理一件事情都会做好最坏的打算。
OK~,编程中的无锁技术,或者说乐观锁机制,一般都是基于CAS思想实现的,而在MySQL中则可以通过version版本号+CAS的形式实现乐观锁,也就是在表中多设计一个version字段,然后在SQL修改时以如下形式操作:
UPDATE ... SET version = version + 1 ... WHERE ... AND version = version;
也就是每条修改的SQL都在修改后,对version字段加一,比如T1、T2两个事务一起并发执行时,当T2事务执行成功提交后,就会对version+1,因此事务T1的version=version这个条件就无法成立,最终会放弃执行,因为已经被其他事务修改过了。
当然,一般的乐观锁都会配合轮询重试机制,比如上述T1执行失败后,再次执行相同语句,直到成功为止。
从上述过程中不难看出,这个过程中确实未曾添加锁,因此也做到了乐观锁/无锁的概念落地,但这种形式却并不适合所有情况,比如写操作的并发较高时,就容易导致一个事务长时间一直在重试执行,从而导致客户端的响应尤为缓慢。
因此乐观锁更加适用于读大于写的业务场景,频繁写库的业务则并不适合加乐观锁。
悲观锁
悲观锁的思想咱们上面已经提到了,即每次执行时都会加锁再执行,咱们之前分析的《synchronized关键字》、《AQS-ReetrantLock》都属于悲观锁类型,也就是在每次执行前必须获取到锁,然后才能继续往下执行,而数据库中的排他锁,就是一种典型的悲观锁类型。
在数据库中想要使用悲观锁,那也就是对一个事务加排他锁for update即可,不再重复赘述。
MySQL锁机制总结
看到这里,相信大家对MySQL中提供的锁机制有了全面的认识,但以目前情况而言,虽对每种锁类型有了基本认知,但本篇的内容更像一个个的点,很难和《MySQL事务篇》连成线,而对于这块的具体内容,则会放在后续的《事务与锁机制的实现原理篇》中详细讲解,在后续的原理篇中再将这一个个知识点串联起来,因为想要真正弄懂MySQL事务隔离机制的实现,还缺少了一块至关重要的点没讲到:即MVCC机制。
因此会先讲明白数据库的MVCC多版本并发控制技术的实现后,再去剖析事务隔离机制的实现。
最后再来简单的总结一下本篇所聊到的不同锁,它们之间的冲突与兼容关系:
PS:表中横向(行)表示已经持有锁的事务,纵向(列)表示正在请求锁的事务。
| 行级锁对比 | 共享临键锁 | 排他临键锁 | 间隙锁 | 插入意向锁 |
|---|---|---|---|---|
| 共享临键锁 | 兼容 | 冲突 | 兼容 | 冲突 |
| 排他临键锁 | 冲突 | 冲突 | 兼容 | 冲突 |
| 间隙锁 | 兼容 | 兼容 | 兼容 | 冲突 |
| 插入意向锁 | 冲突 | 冲突 | 冲突 | 兼容 |
由于临建锁也会锁定相应的行数据,因此上表中也不再重复赘述记录锁,临建锁兼容的 记录锁都兼容,同理,冲突的记录锁也会冲突,再来看看标记别的锁对比:
| 表级锁对比 | 共享意向锁 | 排他意向锁 | 元数据锁 | 自增锁 | 全局锁 |
|---|---|---|---|---|---|
| 共享意向锁 | 兼容 | 冲突 | 冲突 | 冲突 | 冲突 |
| 排他意向锁 | 冲突 | 冲突 | 冲突 | 冲突 | 冲突 |
| 元数据锁 | 冲突 | 冲突 | 冲突 | 冲突 | 冲突 |
| 自增锁 | 冲突 | 冲突 | 冲突 | 冲突 | 冲突 |
| 全局锁 | 兼容 | 冲突 | 冲突 | 冲突 | 冲突 |
放眼望下来,其实会发现表级别的锁,会有很多很多冲突,因为锁的粒度比较大,因此很多时候都会出现冲突,但对于表级锁,咱们只需要关注共享意向锁和共享排他锁即可,其他的大多数为MySQL的隐式锁(在这里,共享意向锁和排他意向锁,也可以理解为MyISAM中的表读锁和表写锁)。
最后再简单的说一下,表中的冲突和兼容究竟是啥意思?冲突的意思是当一个事务T1持有某个锁时,另一个事务T2来请求相同的锁,T2会由于锁排斥会陷入阻塞等待状态。反之同理,兼容的意思是指允许多个事务一同获取同一个锁。
MySQL5.7版本中新增的共享排他锁
对于这条是最后补齐的,之前漏写了这种锁类型,在MySQL5.7之前的版本中,数据库中仅存在两种类型的锁,即共享锁与排他锁,但是在MySQL5.7.2版本中引入了一种新的锁,被称之为(SX)共享排他锁,这种锁是共享锁与排他锁的杂交类型,至于为何引入这种锁呢?聊它之前需要先理解SMO问题:
在SQL执行期间一旦更新操作触发B+Tree叶子节点分裂,那么就会对整棵B+Tree加排它锁,这不但阻塞了后续这张表上的所有的更新操作,同时也阻止了所有试图在B+Tree上的读操作,也就是会导致所有的读写操作都被阻塞,其影响巨大。因此,这种大粒度的排它锁成为了InnoDB支持高并发访问的主要瓶颈,而这也是MySQL5.7版本中引入SX锁要解决的问题。
那想一下该如何解决这个问题呢?最简单的方式就是减小SMO问题发生时,锁定的B+Tree粒度,当发生SMO问题时,就只锁定B+Tree的某个分支,而并不是锁定整颗B+树,从而做到不影响其他分支上的读写操作。
那MySQL5.7中引入共享排他锁后,究竟是如何实现的这点呢?首先要弄清楚SX锁的特性,它不会阻塞S锁,但是会阻塞X、SX锁,下面展开来聊一聊。
在聊之前首先得搞清楚SQL执行时的几个概念:
- 读取操作:基于B+Tree去读取某条或多条行记录。
- 乐观写入:不会改变B+Tree的索引键,仅会更改索引值,比如主键索引树中不修改主键字段,只修改其他字段的数据,不会引起节点分裂。
- 悲观写入:会改变B+Tree的结构,也就是会造成节点分裂,比如无序插入、修改索引键的字段值。
在MySQL5.6版本中,一旦有操作导致了树结构发生变化,就会对整棵树加上排他锁,阻塞所有的读写操作,而MySQL5.7版本中,为了解决该问题,对于不同的SQL执行,流程就做了调整。
MySQL5.7中读操作的执行流程
- ①读取数据之前首先会对B+Tree加一个共享锁。
- ②在基于树检索数据的过程中,对于所有走过的叶节点会加一个共享锁。
- ③找到需要读取的目标叶子节点后,先加一个共享锁,释放步骤②上加的所有共享锁。
- ④读取最终的目标叶子节点中的数据,读取完成后释放对应叶子节点上的共享锁。
MySQL5.7中乐观写入的执行流程
- ①乐观写入之前首先会对B+Tree加一个共享锁。
- ②在基于树检索修改位置的过程中,对于所有走过的叶节点会加一个共享锁。
- ③找到需要写入数据的目标叶子节点后,先加一个排他锁,释放步骤②上加的所有共享锁。
- ④修改目标叶子节点中的数据后,释放对应叶子节点上的排他锁。
MySQL5.7中悲观写入的执行流程
- ①悲观更新之前首先会对B+Tree加一个共享排他锁。
- ②由于①上已经加了SX锁,因此当前事务执行过程中会阻塞其他尝试更改树结构的事务。
- ③遍历查找需要写入数据的目标叶子节点,找到后对其分支加上排他锁,释放①中加的SX锁。
- ④执行SMO操作,也就是执行悲观写入操作,完成后释放步骤③中在分支上加的排他锁。
如果需要修改多个数据时,会在遍历查找的过程中,记录下所有要修改的目标节点。
MySQL5.7中并发事务冲突分析
观察上述讲到的三种执行情况,对于读操作、乐观写入操作而言,并不会加SX锁,共享排他锁仅针对于悲观写入操作会加,由于读操作、乐观写入执行前对整颗树加的是S锁,因此悲观写入时加的SX锁并不会阻塞乐观写入和读操作,但当另一个事务尝试执行SMO操作变更树结构时,也需要先对树加上一个SX锁,这时两个悲观写入的并发事务就会出现冲突,新来的事务会被阻塞。
但是要注意:当第一个事务寻找到要修改的节点后,会对其分支加上X锁,紧接着会释放B+Tree上的SX锁,这时另外一个执行SMO操作的事务就能获取SX锁啦!
其实从上述中可能得知一点:MySQL5.7版本引入共享排他锁之后,解决了5.6版本发生SMO操作时阻塞一切读写操作的问题,这样能够在一定程度上提升了InnoDB表的并发性能。
最后要注意:虽然一个执行悲观写入的事务,找到了要更新/插入数据的节点后会释放SX锁,但是会对其上级的叶节点(叶分支)加上排他锁,因此正在发生SMO操作的叶分支,依旧是会阻塞所有的读写行为!
上面这句话啥意思呢?也就是当一个要读取的数据,位于正在执行SMO操作的叶分支中时,依旧会被阻塞。